

目录
快速导航-
卷首语 | 数智时代语言规划须顺势而为
卷首语 | 数智时代语言规划须顺势而为
-
专题研究一 大语言模型 | 主持人语 大语言模型与语言研究的双向赋能与融合发展
专题研究一 大语言模型 | 主持人语 大语言模型与语言研究的双向赋能与融合发展
-
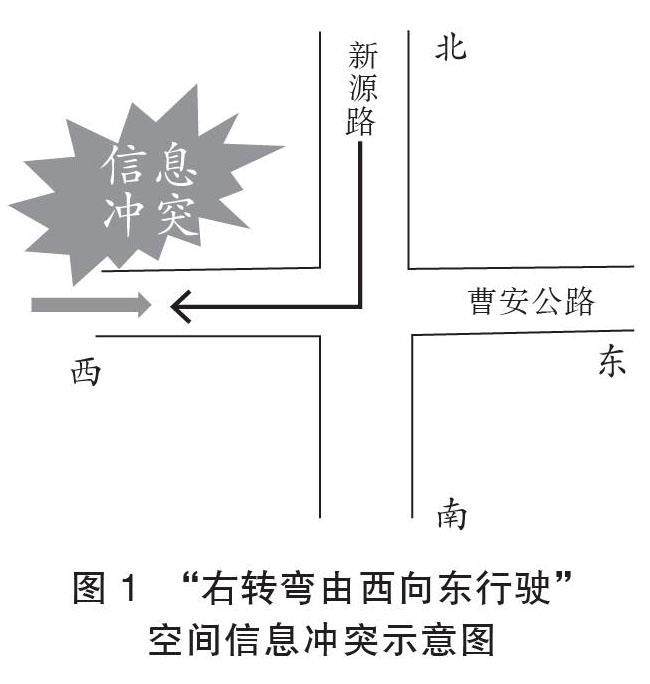
专题研究一 大语言模型 | 语言学知识驱动的空间语义理解能力评测数据集研究
专题研究一 大语言模型 | 语言学知识驱动的空间语义理解能力评测数据集研究
-
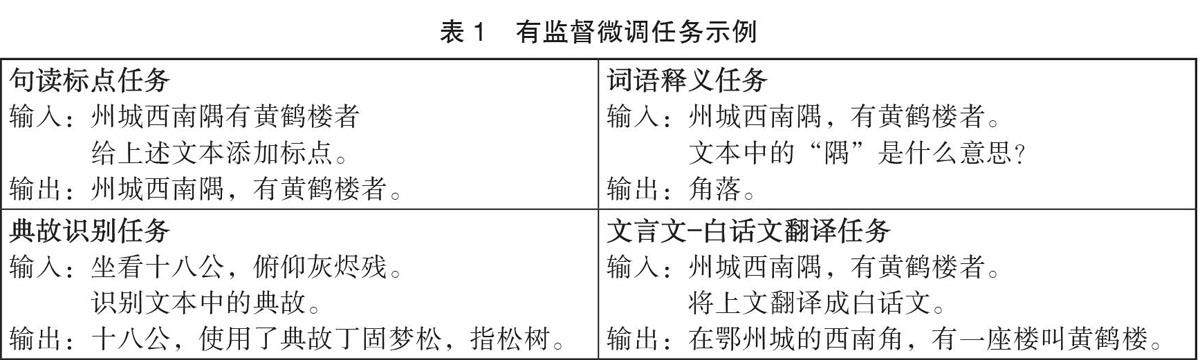
专题研究一 大语言模型 | 古汉语大语言模型的构建及应用研究
专题研究一 大语言模型 | 古汉语大语言模型的构建及应用研究
-

专题研究一 大语言模型 | 大语言模型的中文文本简化能力研究
专题研究一 大语言模型 | 大语言模型的中文文本简化能力研究
-
专题研究一 大语言模型 | “大语言模型”多人谈
专题研究一 大语言模型 | “大语言模型”多人谈
-
专题研究二 国际中文教育 | 主持人语 中文二语教学大时代的几点小思考
专题研究二 国际中文教育 | 主持人语 中文二语教学大时代的几点小思考
-

专题研究二 国际中文教育 | 论“人群特征”对国际中文教育的学科支撑
专题研究二 国际中文教育 | 论“人群特征”对国际中文教育的学科支撑
-
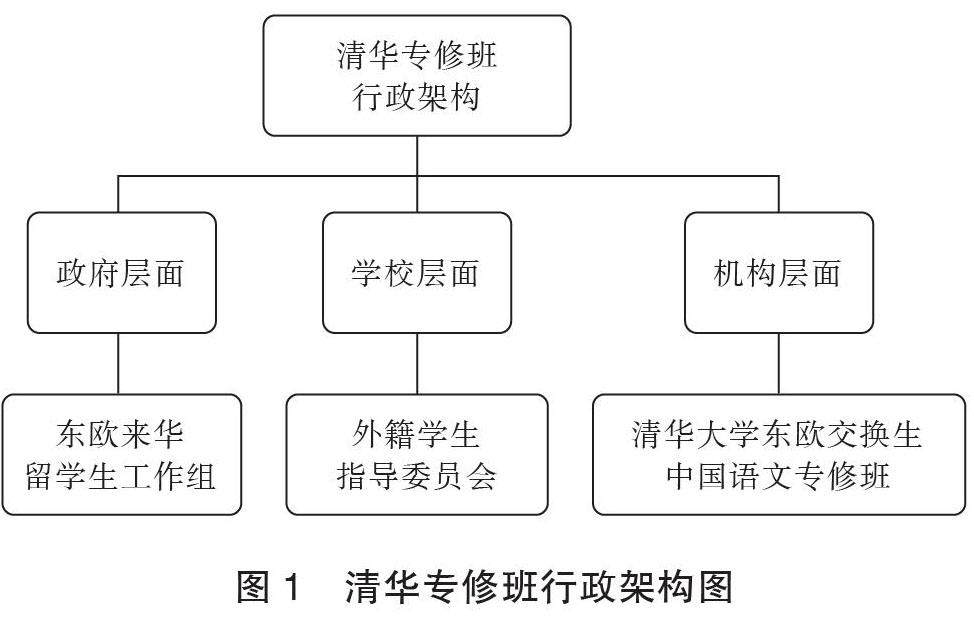
专题研究二 国际中文教育 | 清华大学东欧交换生中国语文专修班建班考
专题研究二 国际中文教育 | 清华大学东欧交换生中国语文专修班建班考
-
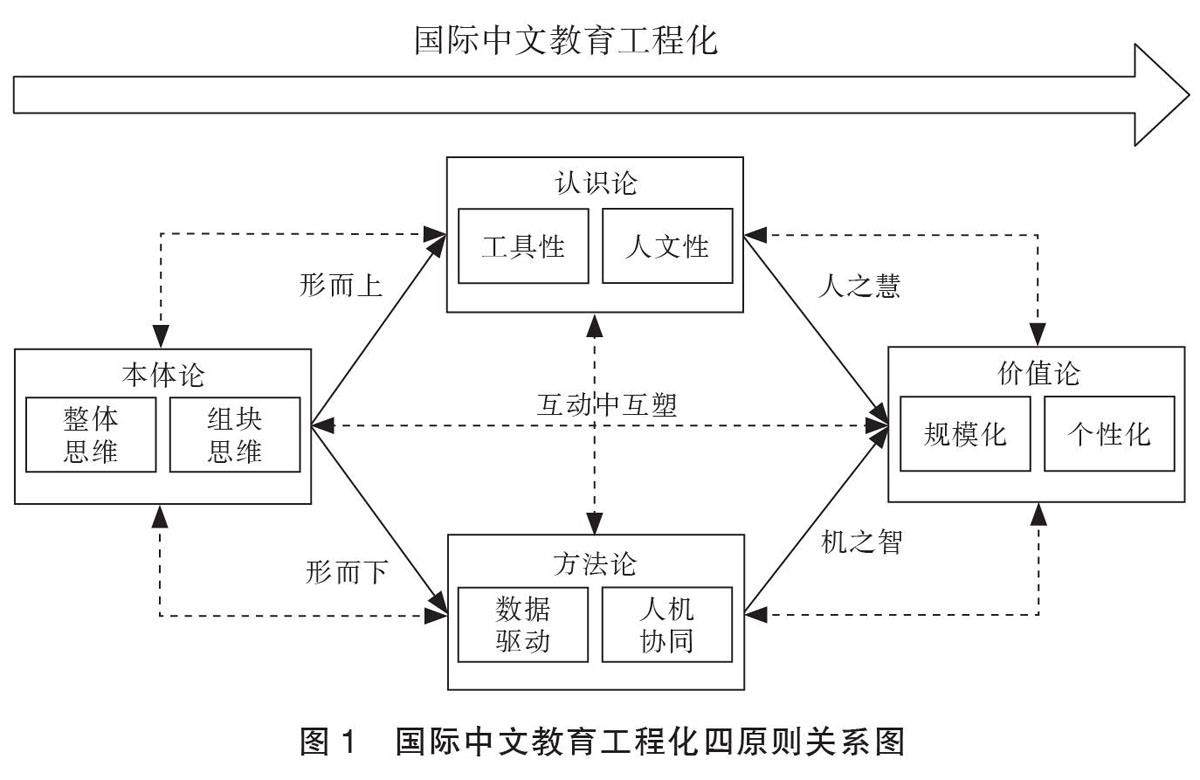
专题研究二 国际中文教育 | 国际中文教育工程化的内涵、特征和原则
专题研究二 国际中文教育 | 国际中文教育工程化的内涵、特征和原则
-
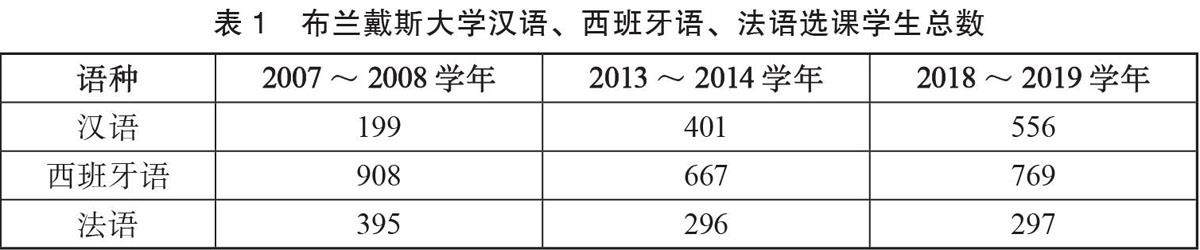
专题研究二 国际中文教育 | 从汉英语作为外语教学的差异试议智能时代的汉语教学
专题研究二 国际中文教育 | 从汉英语作为外语教学的差异试议智能时代的汉语教学
-
专题研究二 国际中文教育 | “国际中文教育”多人谈
专题研究二 国际中文教育 | “国际中文教育”多人谈















 登录
登录