

目录
快速导航-
卷首语 | 卷首语
卷首语 | 卷首语
-
特约稿件 | 生成式AI视域下智慧图书馆建设的关键路径
特约稿件 | 生成式AI视域下智慧图书馆建设的关键路径
-
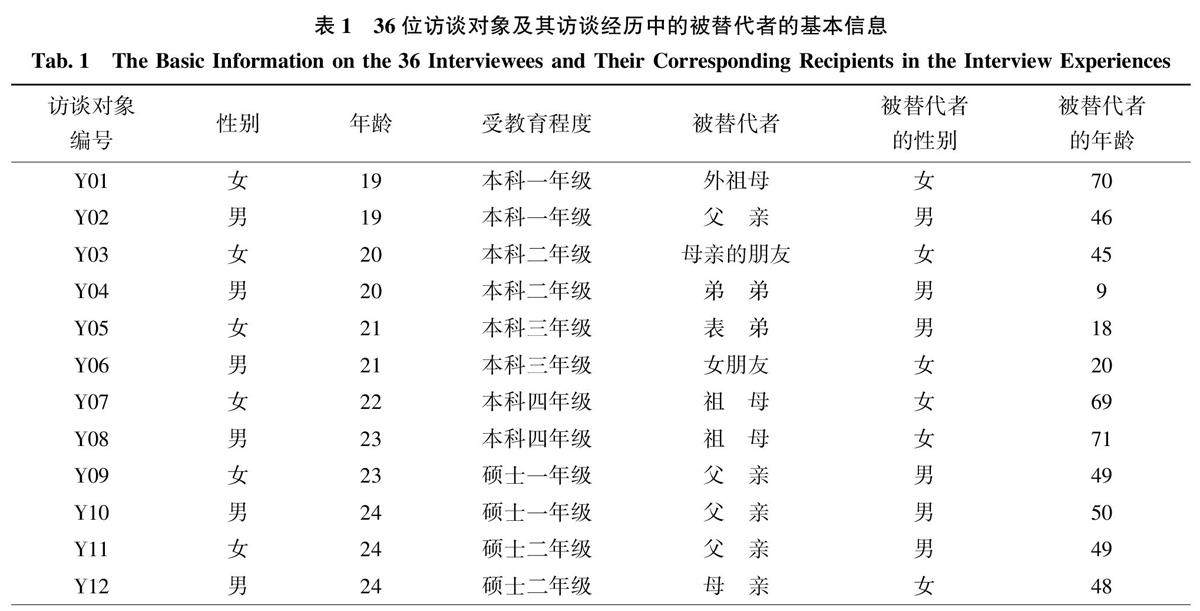
特约稿件 | 健康信息替代搜寻行为的类型、过程、特征和模型研究
特约稿件 | 健康信息替代搜寻行为的类型、过程、特征和模型研究
-

情报分析与技术创新 | 基于多粒度标签扰动的文本分类研究
情报分析与技术创新 | 基于多粒度标签扰动的文本分类研究
-
情报分析与技术创新 | 基于神经网络词嵌入的大数据关注热点和词嵌入概貌比较研究
情报分析与技术创新 | 基于神经网络词嵌入的大数据关注热点和词嵌入概貌比较研究
-
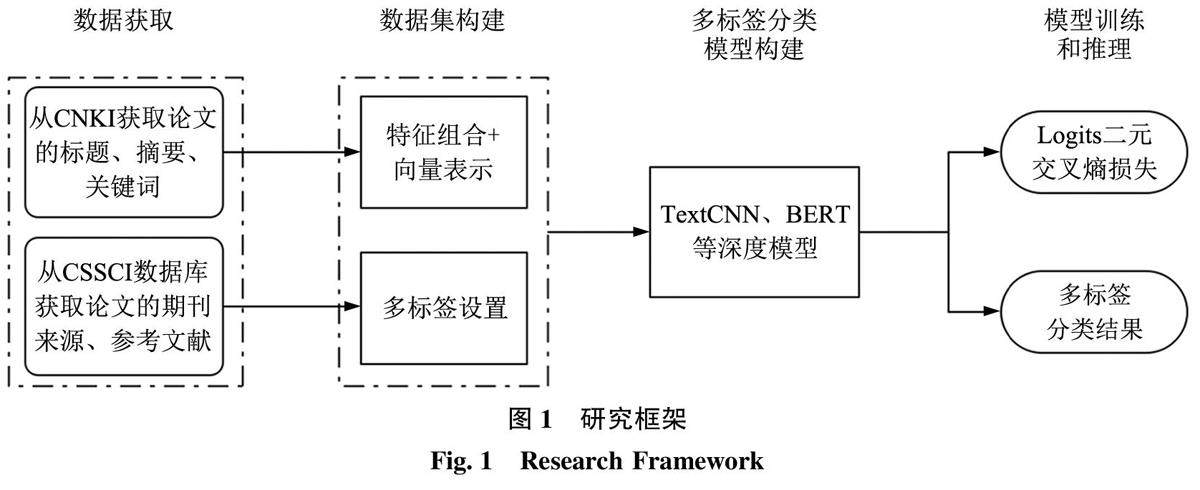
情报分析与技术创新 | 面向投稿选刊的学术论文多标签分类研究
情报分析与技术创新 | 面向投稿选刊的学术论文多标签分类研究
-

信息行为与用户研究 | 美感与情感:美学视角下的个体交互感知机制研究
信息行为与用户研究 | 美感与情感:美学视角下的个体交互感知机制研究
-

信息行为与用户研究 | 互动仪式链视角下的电商直播用户参与行为影响因素研究
信息行为与用户研究 | 互动仪式链视角下的电商直播用户参与行为影响因素研究
-
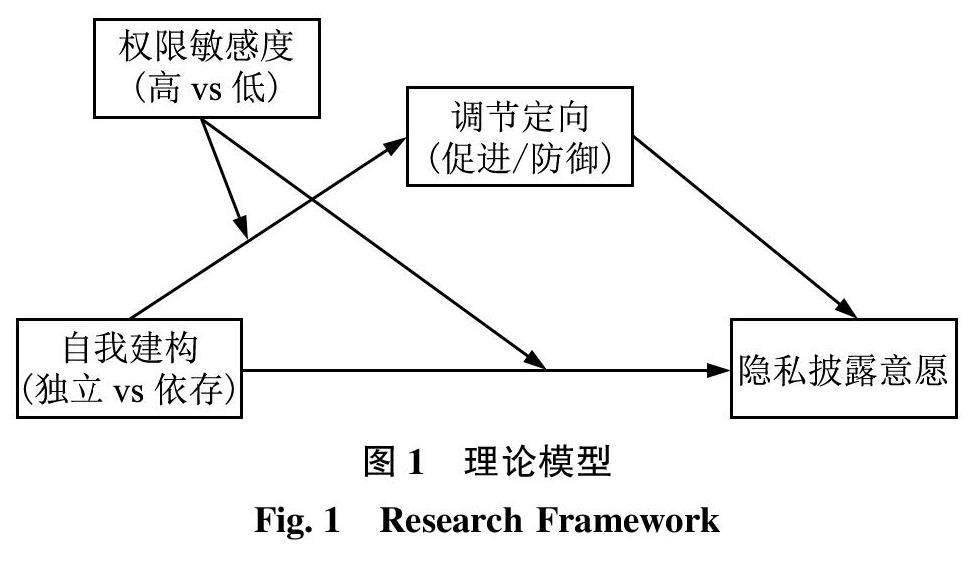
信息行为与用户研究 | 自我建构视角下个体隐私披露意愿的差异性研究
信息行为与用户研究 | 自我建构视角下个体隐私披露意愿的差异性研究
-
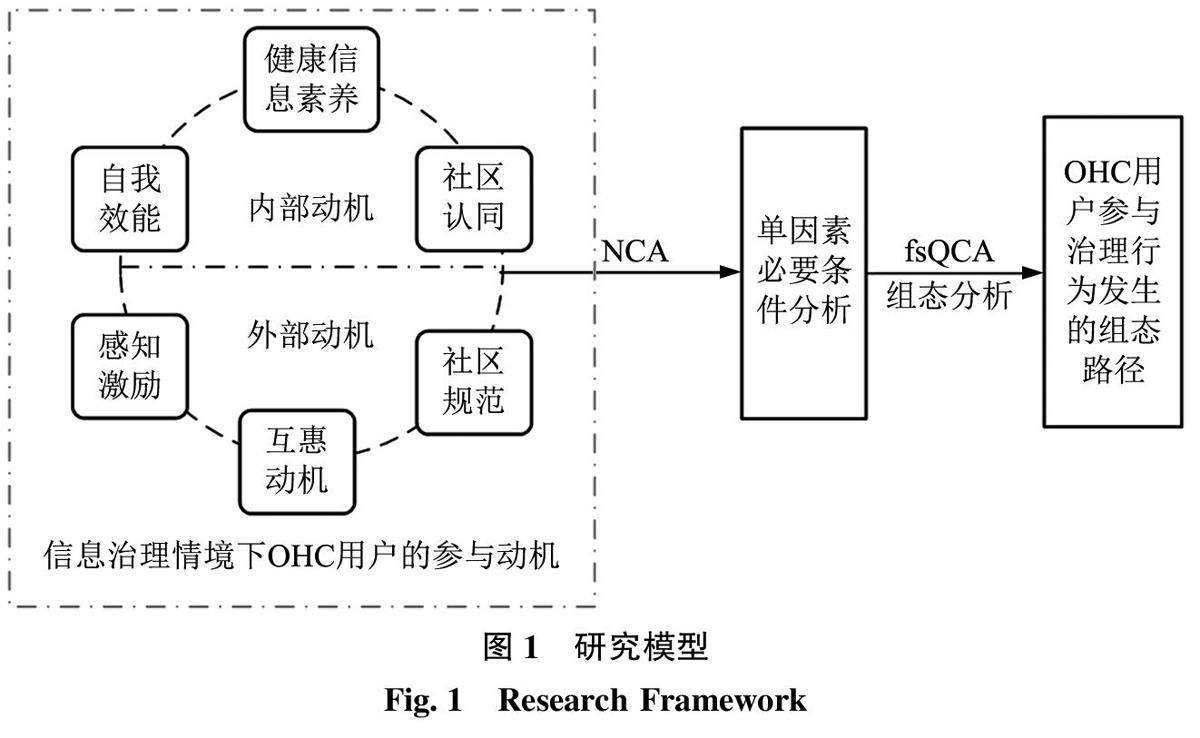
数据共享与数据治理 | 在线健康社区用户参与动机对参与治理行为的组态效应研究
数据共享与数据治理 | 在线健康社区用户参与动机对参与治理行为的组态效应研究
-

数据共享与数据治理 | 我国省级政府数据开放平台服务的优化策略研究
数据共享与数据治理 | 我国省级政府数据开放平台服务的优化策略研究
-
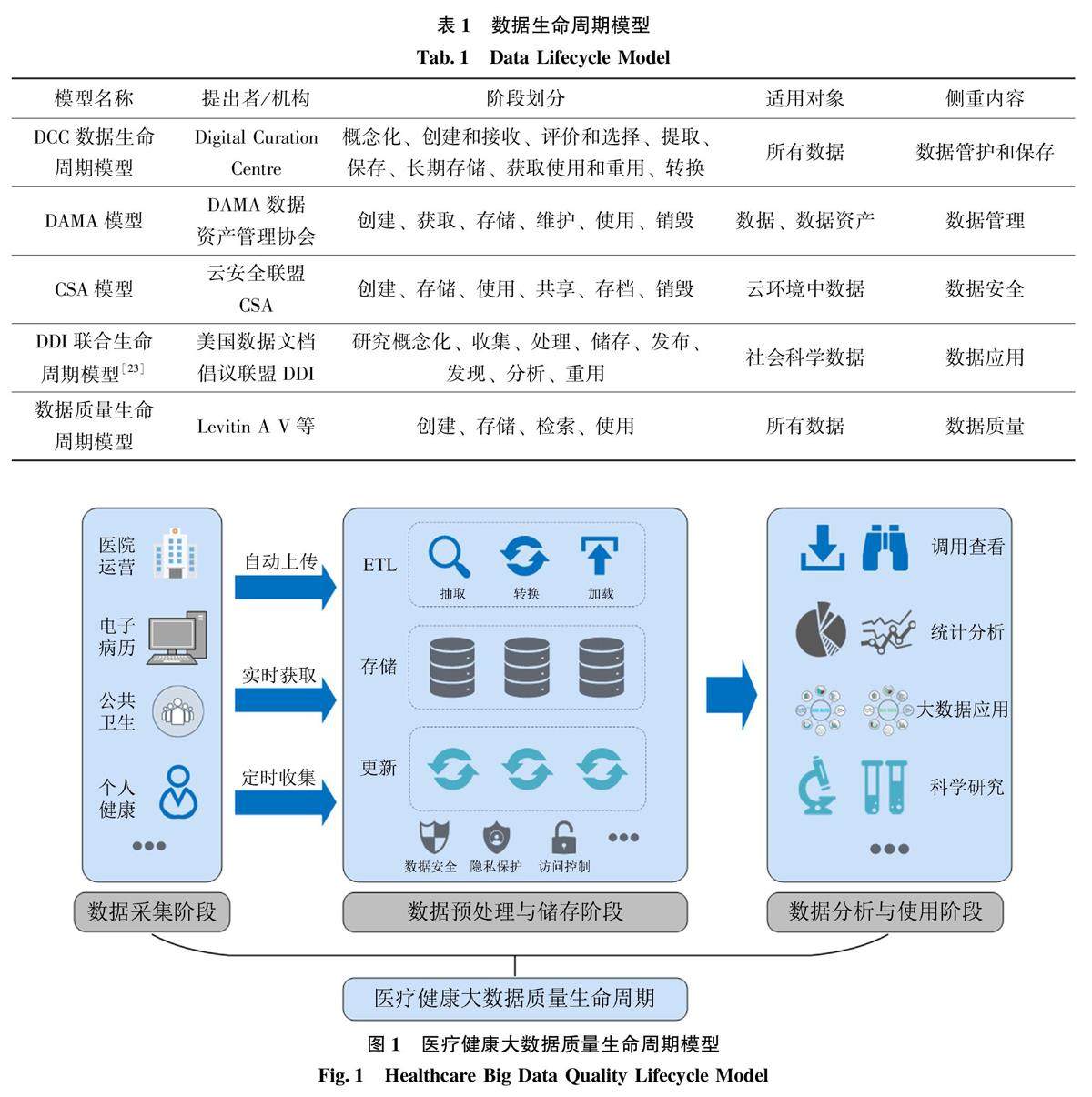
数据共享与数据治理 | 数据生命周期视角下的医疗健康大数据质量评价研究
数据共享与数据治理 | 数据生命周期视角下的医疗健康大数据质量评价研究
-
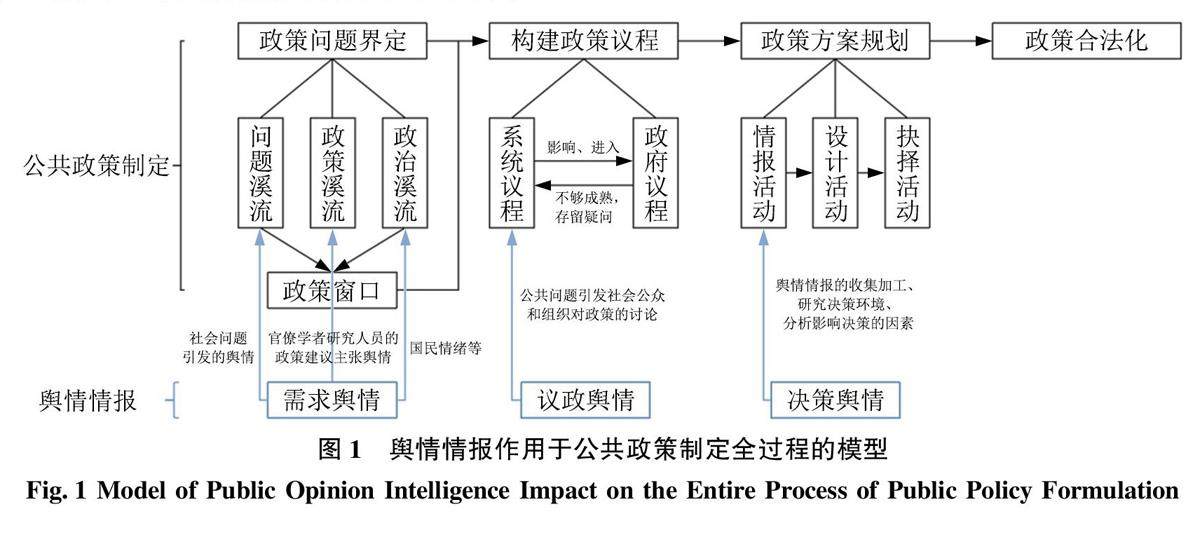
情报业务与情报服务 | 面向公共政策制定全过程的舆情情报服务框架研究
情报业务与情报服务 | 面向公共政策制定全过程的舆情情报服务框架研究
-

情报业务与情报服务 | 基于组合的情报分析构件化研究
情报业务与情报服务 | 基于组合的情报分析构件化研究
-

信息计量与科学评价 | 融合Altmetrics指标的领域高产学者综合影响力研究
信息计量与科学评价 | 融合Altmetrics指标的领域高产学者综合影响力研究
-

信息计量与科学评价 | 地理邻近性对专利技术转移速度的影响研究
信息计量与科学评价 | 地理邻近性对专利技术转移速度的影响研究




















 登录
登录